1. Introducción y Objetivo del Proyecto
MoneyTop es una empresa fintech enfocada en ofrecer soluciones innovadoras de servicios financieros a través de plataformas digitales.
El objetivo principal de este proyecto es segmentar la base de clientes de MoneyTop mediante técnicas de clustering, con el fin de identificar patrones de comportamiento y características comunes entre los usuarios.
El rol del analista de datos es desarrollar un modelo de clustering que agrupe a los clientes en función de variables relevantes. Los clusters generados deben ser lo suficientemente representativos y distinguirse entre sí de manera clara para activar estrategias diferenciadas de marketing y mejorar la experiencia del cliente.
2. Etapas del Proyecto
2.1 Análisis y Preparación de los Datos
La primera etapa consiste en la integración y limpieza de los datos. Para ello, se unieron las diferentes tablas que contienen la información de los usuarios y los productos utilizando SQL.
En total la base de datos era de 450.000 clientes, y cada cliente contaba con un total de 25 variables.
Una vez integrados, se procedió con la exploración y limpieza de los datos para eliminar inconsistencias y datos faltantes, asegurando la calidad de la base sobre la que trabajaremos.
2.2 Selección de Variables para la Segmentación
Después de analizar las variables disponibles y comprender las necesidades del negocio, se seleccionaron los factores más relevantes para segmentar a los clientes. En este caso, las variables elegidas fueron:
- Edad: Se definieron 4 grupos:
- Menores de 18 años
- Jóvenes adultos (18-30 años)
- Trabajadores (31-60 años)
- Jubilados (mayores de 60 años)
def categorizar_edad(edad):
if edad <= 17:
return 'Menores de Edad'
elif edad <= 30:
return 'Jovenes Adultos'
elif edad <= 65:
return 'Trabajadores'
else:
return 'Jubilados'df['age_group'] = df['age'].apply(categorizar_edad)2. Zona Geográfica: Se categorizó a los clientes según la región en la que residen, utilizando los siguientes grupos:
- Ciudades grandes
- Ciudades medianas
- Ciudades pequeñas
3. Productos Financieros Contratados: Dado que MoneyTop ofrece más de 15 productos financieros, los productos fueron agrupados en tres categorías:
- Productos de ahorro
- Productos de financiación
- Productos de inversión
2.3 Preparación y Filtrado del Dataset para el Clustering
Una vez que las nuevas variables fueron incorporadas, se procedió a filtrar el dataset para centrarse exclusivamente en las variables seleccionadas para el análisis de clustering. El conjunto de datos final contenía las variables relevantes que se utilizarían en el modelo de segmentación.
2.4 Implementación del Algoritmo K-Means
El siguiente paso fue la aplicación del algoritmo de clustering K-Means. Este algoritmo agrupa a los clientes en distintos clústeres, en función de las características similares de las variables seleccionadas.
K-Means es un algoritmo de aprendizaje no supervisado que busca dividir un conjunto de datos en un número predefinido de grupos (clústeres). El algoritmo asigna a cada cliente el grupo con el que más se asemeja en función de sus características.
2.5 Determinación del Número de Clústeres (Elbow Curve)
Para decidir el número adecuado de clústeres (K), se generó la elbow curve. Esta curva muestra la variación de la suma de las distancias cuadradas de los puntos de datos a los centros de los clústeres a medida que aumenta el número de clústeres.
La elbow curve ayuda a identificar el valor óptimo de K, que es el punto donde la pendiente de la curva se vuelve menos pronunciada (el «codo»). Este punto indica que agregar más clústeres no mejora significativamente el modelo, por lo que se seleccionó ese número como el más adecuado.

2.6 Segmentación y Análisis de Clústeres
Una vez determinado el número óptimo de clústeres, se segmentó a los clientes de acuerdo con el modelo K-Means.
El análisis de los clústeres resultantes permitió identificar cinco grupos de clientes con características y comportamientos comunes. Cada grupo se analizó detalladamente para entender sus necesidades y características, lo que permitió extraer insights valiosos.
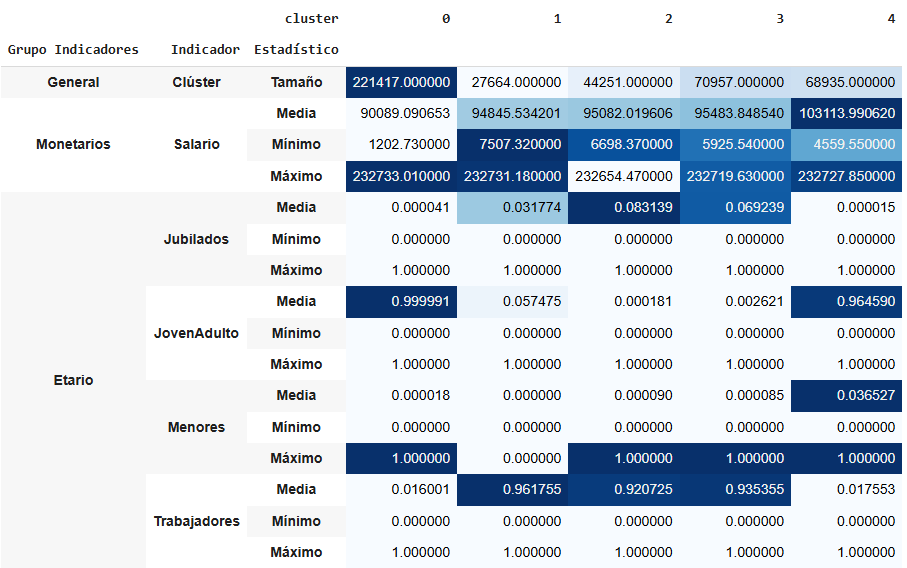
2.7 Resultados: Descripción de los Clústeres
Tras la segmentación, se identificaron los siguientes cinco grupos de clientes:
- Grupo 1: «Ahorro joven»: Jóvenes adultos con productos de ahorro. Este grupo es muy consciente de la importancia de ahorrar y está comenzando su trayectoria financiera.
- Grupo 2: «Inversores urbanos»: Adultos trabajadores que residen en grandes ciudades y están interesados en productos de inversión. Buscan diversificar sus activos y maximizar sus rendimientos.
- Grupo 3: «Jubilados con productos de financiación»: Personas mayores que residen en ciudades pequeñas o medianas, con una preferencia por productos de financiación debido a necesidades de liquidez.
- Grupo 4: «Familias de clase media»: Adultos trabajadores en ciudades medianas, que optan por una mezcla de productos de ahorro y financiación, buscando estabilidad y crecimiento moderado.
- Grupo 5: «Inversores de altos ingresos»: Clientes de mayores ingresos con preferencia por productos de inversión, que buscan aumentar su riqueza a través de instrumentos financieros complejos.
2.8 Acciones de Marketing y Decisiones Estratégicas
El siguiente paso en el proyecto será trabajar junto al equipo de negocio y marketing para aplicar las estrategias correspondientes a cada segmento.
Con base en los insights obtenidos de los clústeres, se podrán personalizar las campañas de marketing y ofrecer productos específicos para cada grupo, lo que incrementará la efectividad de las campañas y la satisfacción del cliente.
