1. Introducción y Objetivo del Proyecto de Machine Learning
Telco, empresa telefónica, enfrenta un desafío significativo: la disminución en el número de suscriptores activos debido a un aumento en las cancelaciones durante los últimos meses. Este problema no solo impacta los ingresos recurrentes, sino también la reputación y estabilidad de la empresa.
Para contrarrestar esta situación, la empresa ha decidido aprovechar el poder de los datos. El objetivo es lanzar una campaña de retención enfocada en identificar y contactar a los suscriptores con mayor probabilidad de baja, ofreciéndoles descuentos y beneficios exclusivos para fomentar la renovación de sus membresías por un año adicional.
El rol del analista de datos en este contexto es desarrollar un modelo predictivo que identifique qué socios están en riesgo de cancelar su membresía el próximo mes. Este modelo permitirá a los equipos de marketing y atención al cliente optimizar recursos y ejecutar estrategias de retención de manera más eficaz.
2. Análisis del contexto interno y externo
Comprender el Modelo de Negocio de Telco (Contexto Interno)
El primer paso para el éxito del proyecto es entender a fondo el modelo de negocio de Telco. Este análisis permitirá que el modelo predictivo refleje con precisión las particularidades del negocio y sus clientes.
Aspectos clave a analizar:
- Modelo de suscripción: Comprender los diferentes planes que ofrece Telco (mensuales, trimestrales o anuales).
- Segmentación de clientes: Identificar diferentes perfiles de socios (frecuentes, esporádicos, nuevos, etc.).
Este conocimiento es esencial para adaptar el modelo de predicción a las necesidades específicas del negocio y permite anticipar los patrones de comportamiento de los suscriptores.
Análisis del Contexto Externo (Competencia y Tendencias del Sector)
Además de analizar el contexto interno, es fundamental estudiar el entorno externo y las tendencias del mercado.
Benchmarking de la competencia:
- Identificar los principales competidores.
- Analizar sus estrategias de retención, precios, descuentos y promociones.
Tendencias del sector:
- Estacionalidad de las altas y bajas (por ejemplo, picos de inscripciones en enero y cancelaciones en verano).
- Innovaciones tecnológicas
El análisis externo proporcionará ideas y buenas prácticas que podrán integrarse en las estrategias de Telco, alineándolas con las expectativas del mercado.
3. Preparación del Modelo Predictivo
Una vez completado el análisis interno y externo, se inicia la fase de construcción del modelo predictivo.
Definición del Problema: El objetivo del modelo es predecir si un suscriptor cancelará su membresía el mes siguiente (problema de clasificación binaria: SÍ o No).
Conexión con los Datos: Se establece una conexión a la base de datos mediante SQL para acceder a la información histórica de los socios.
Análisis Exploratorio de Datos (EDA) + Data Cleaning
- Primeras observaciones
- Análisis univariable para entender la distribución de cada característica
- Definimos el target y las features
- Analizamos las distribuciones del target y de las features
- Eliminación de datos duplicados.
- Imputación de valores nulos.
- Formateo de variables (unificación de formatos de fecha, texto, etc.).
- Codificación de variables categóricas (encoding).
- Eliminación de variables con alta correlación o baja varianza.
# Check duplicados
df.duplicated().sum()
# Check filas sin target
df['churn'].isna().sum()
# Check análisis univariables
for i in list(df.select_dtypes(include='object').columns):
print(i)
print('Unique:',df[i].nunique())
print(df[i].value_counts(),'\n')
# Encoding categóricos
df = pd.get_dummies(df, columns=lista_categoricas)Separación en Conjuntos de Entrenamiento y Test: Se divide el conjunto de datos en training (70%) y test (30%).
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)Escalado de Variables: Rescaling de las variables numéricas para normalizar los datos y evitar sesgos durante el entrenamiento.
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)
X_train_std = pd.DataFrame(X_train_std, columns = X_train.columns, index= X_train.index)
X_test_std = pd.DataFrame(X_test_std, columns = X_test.columns, index= X_test.index)4. Selección y Validación del Modelo
Torneo de Modelos: Se prueba con diferentes algoritmos de clasificación, como:
- LGBM Classifier
- Random Forest.
- XGBoost.
- Redes Neuronales.
evaluate_classification(model = RandomForestClassifier(),
X=X_train, y=y_train)Ajuste de Hiperparámetros: Se realiza una optimización mediante Randomized Search o Grid Search para mejorar el rendimiento del modelo.
search_hp = RandomizedSearchCV(estimator = lgb.LGBMClassifier(),
param_distributions = parametros_hp,
scoring = 'roc_auc',
cv = 4,
n_iter = 100,
n_jobs=-1,
verbose=True)Selección del Modelo Final: Se elige el modelo con mejor rendimiento (basado en métricas como accuracy, recall, f1-score y curva ROC).
Prueba Final (TEST): El modelo seleccionado se evalúa con el conjunto de test para garantizar su capacidad de generalización.
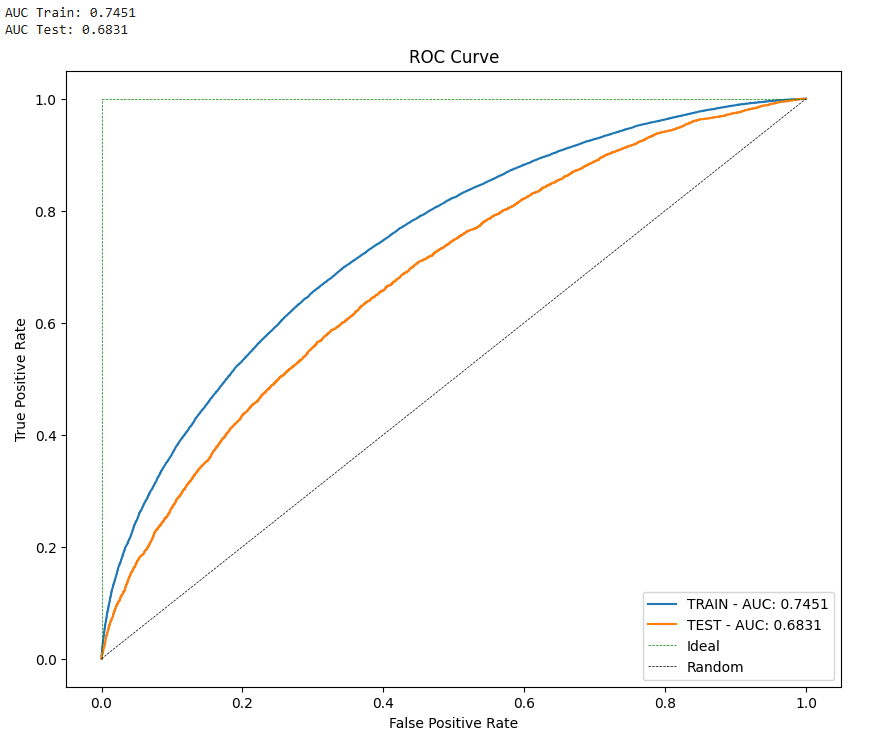
5. Interpretabilidad del modelo
El modelo debe ser interpretable para que los equipos de marketing y atención al cliente puedan entender qué variables afectan más al churn.

Medición de Resultados: Se analizan las top features del modelo para entender el peso que tiene cada una de las variables en el modelo.
De esta forma podemos ver qué factores son los que más influyen en la tasa de abandono de un cliente, y así poder enfocar las estrategias de marketing correctamente.
